Common tasks
- Scoring Prompts: Utilize golden datasets for comparing prompt outputs with ground truths and incorporate human or AI evaluators for quality assessment.
- One-off Bulk Jobs: Ideal for prompt experimentation and iteration.
- Backtesting: Use historical data to build datasets and compare how a new prompt version performs against real production examples.
- Regression Testing: Build evaluation pipelines and datasets to prevent edge-case regression on prompt template updates.
- Continuous Integration: Connect evaluation pipelines to prompt templates to automatically run an eval with each new version (and catologue the results). Think of it like a Github action.
How evaluations fit together
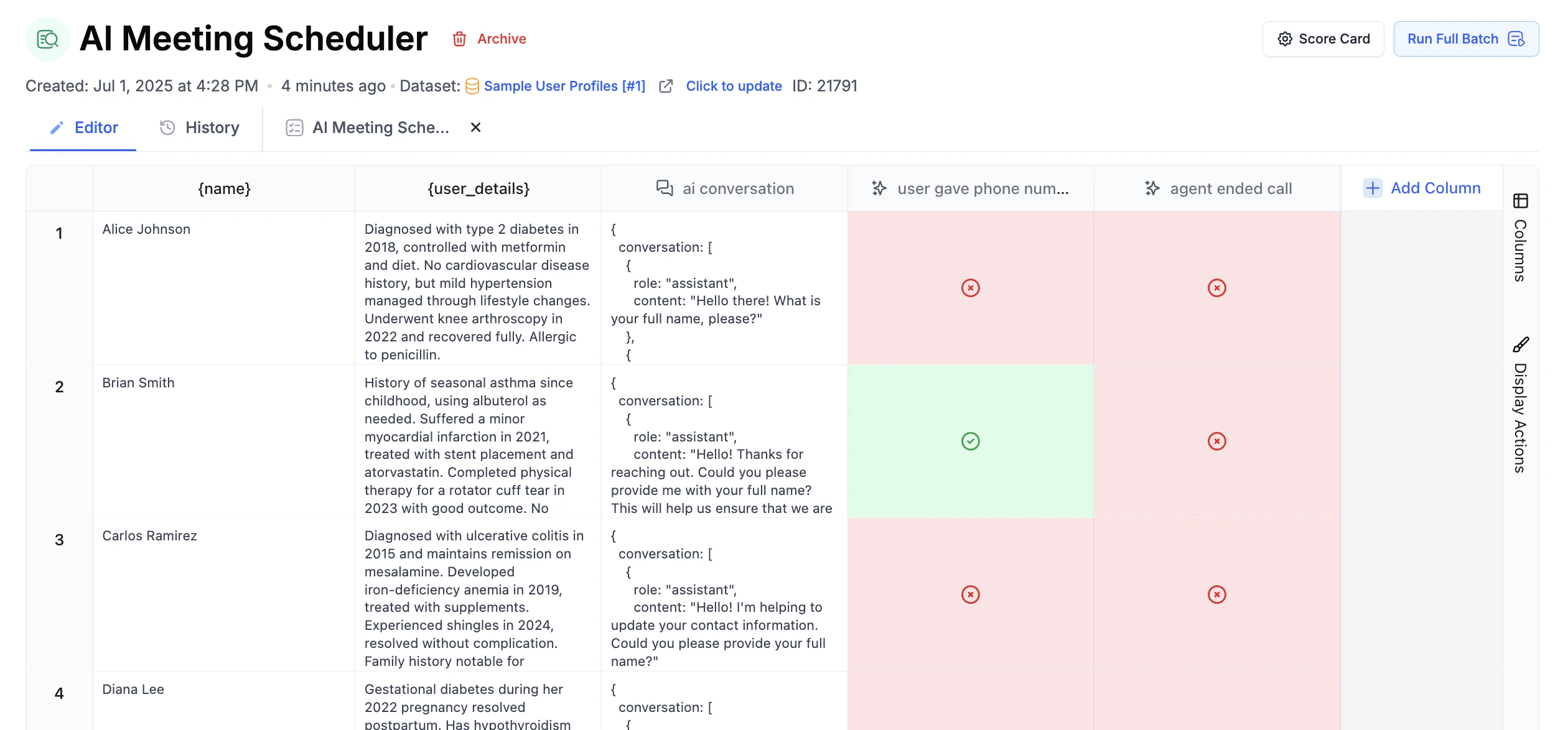
- Create or select a dataset with the inputs you want to test.
- Add one or more Prompt Template columns to generate outputs.
- Add scoring columns such as LLM-as-judge, human grading, equality comparison, cosine similarity, or code evaluators.
- Run the evaluation and review the scorecard, row-level outputs, and diffs.
- Attach the evaluation to a prompt template when you want it to run automatically on new versions.
Example use cases
- Chatbot Enhancements: Improve chatbot interactions by evaluating responses to user requests against semantic criteria.
- RAG System Testing: Build a RAG pipeline and validate responses against a golden dataset.
- SQL Bot Optimization: Test Natural Language to SQL generation prompts by actually running generated queries against a database (using the API Endpoint step), followed by an evaluation of the results’ accuracy.
- Improving Summaries: Combine AI evaluating prompts and human graders to help improve prompts without a ground truth.